

The application: Identifying unknown spectra using custom similarity metrics
When researchers look at mass spectra, they need to identify what kind of metabolite they’re looking at. A large public dataset, GNPS, allows researchers to trawl through existing spectra for a match. But usually matches aren’t exact; they’re just similar. This makes things difficult. We can use machine learning (e.g., Spec2Vec, ML2DeepScore) to find and rank potential matches.
But setting up a machine learning system is challenging. You need a large server, possibly with autoscaling and parallel processing, to train a full Spec2Vec model. And you need a system that periodically pulls the newest data and retrains the models. Setting up and maintaining the required cloud infrastructure is impractical for individual metalomic researchers, and even for many research teams.
We wanted to build a REST API that allowed researchers to easily submit a new spectra as a data point and get the most likely matches as a response, from a managed, always-up-to-date model.
GNPS is updated daily so regularly retraining the models that power the API was important. This article explains how we achieved it using our Open MLOps framework.
System overview: Omigami
We can break our solution into two broad components:
- The data pipeline: downloading the new data, processing it, and training the new models;
- The deployment pipeline: registering and deploying the new models behind a REST API.
In step one, we deal with the data. This is the largest and most complicated part of the project. Every day, we need to download a JSON data file that is many gigabytes in size. We pre-process it into a tabular format and then train the model.
In step two, we make our models accessible as an API. This mainly involves writing YAML to configure Seldon.
This is slightly over-simplified. We can break these two steps down into four sub-components of download, pre-process, train, deploy.
An example of each of these sub-steps is as follows. After new data is added to the GNPS database:
- We schedule automatic downloads of this data;
- We convert the JSON data into tabular data, appropriate for training models;
- We train the models using the Spec2Vec and MS2DeepScore algorithms;
- We register the models in MLFlow and save them to S3, from where Seldon picks them up and deploys them.
This means that whenever a scientist uses the API, they can always access the latest version of the model. This is how:
- A scientist has a spectrum they want to identify;
- They upload this data via our API;
- The API uses the model to find potential matches for the spectrum;
- The API returns these matches to the scientist.
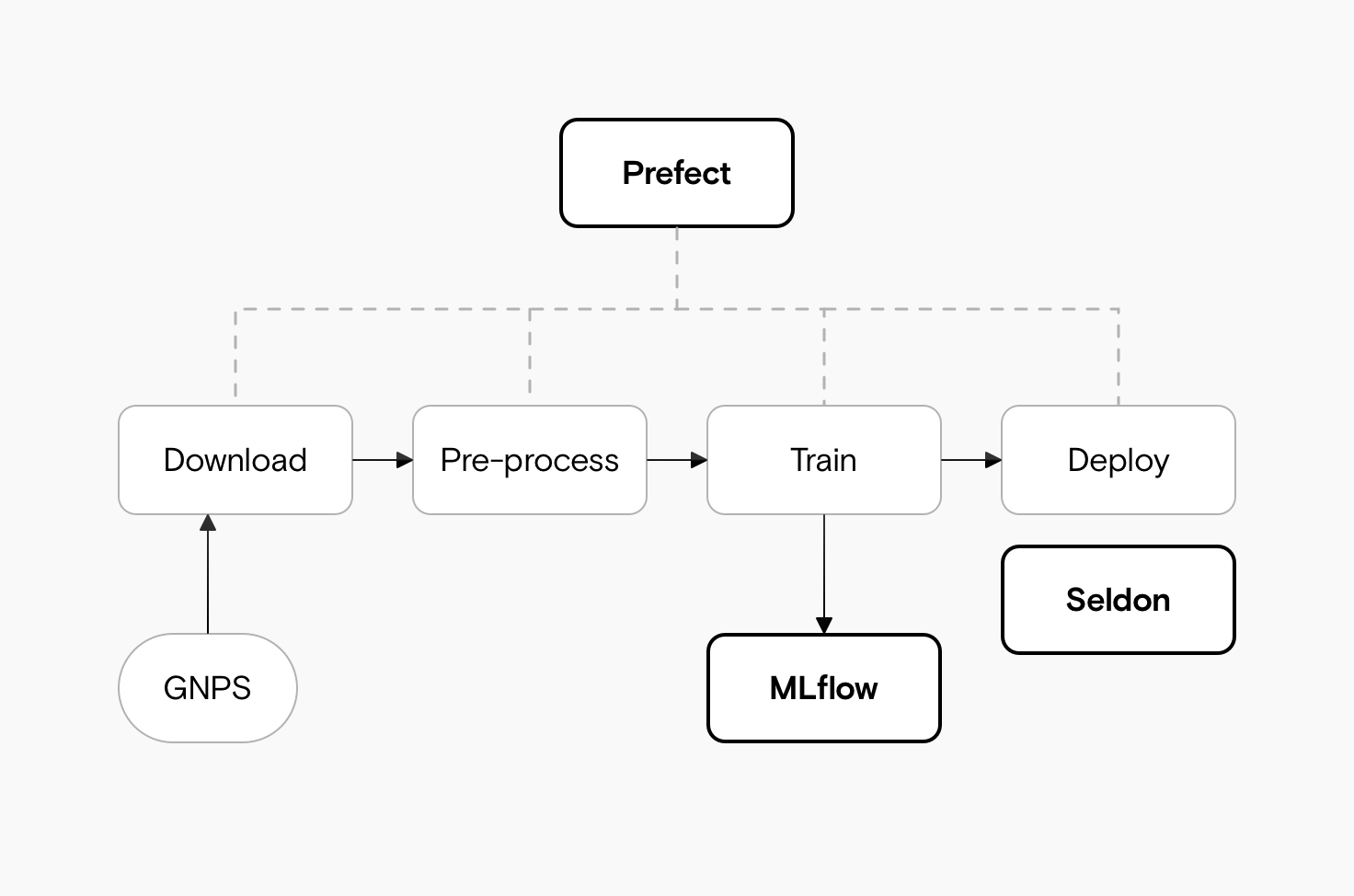
Each step fits nicely into what our Open MLOps framework expects. We use Prefect to maintain an overview of everything. It lets us define and monitor the tasks throughout the whole process. We use MLFlow to keep track of the trained models and link them up to Seldon. And Seldon deploys them behind a REST API and serves requests to the end-user.
Examining the sub-components of our ML solution
Initially, we over-simplified and said our system consisted of two components: the data pipeline and the deployment pipeline. Then we broke this down: download, pre-process, train, deploy. Now let’s go into more detail.
How we use Prefect Tasks to make our solution modular
A nice thing about Prefect is the great overview diagram of your system it builds automatically. You simply define individual tasks and Prefect fits them together.
For example, our TrainModel Prefect task looks something like this:

We use Object-Oriented programming, so our TrainModel task derives from a Prefect Task. We define the __init__ and __run__ methods to train the Word2Vec model on our input data.
Once we’ve trained our model, the RegisterModel task looks very similar. We define the model name based on the time it completed training and save it to MLFlow.

Similarly, we create a Prefect Task for other jobs, like downloading the data and deploying the model. Prefect combines all of the tasks into a Flow and builds up a DAG (Directed Acyclic Graph). Our DAG in this case looks like this:

More specifically, we can define eight distinct components of the system:
- Download data: We pull the latest JSON dump from GNPS.
- Create chunks: We divide the data into chunks. These are loaded into Redis and chunked by their ID, so we can process them in parallel.
- Save raw spectra: We save a persistent copy of the individual spectra.
- Process spectra: We convert the spectra into vectors of “words,” suitable for inputting into Gensim’s Word2Vec.
- Train model: We train an unsupervised model.
- Register model: We log the details of the model to MLFlow and save the binary in S3.
- Make embeddings: We create reference embeddings from the spectra to compare to the data uploaded by users.
- Deploy model: We update our Seldon deployment with the new model.
The advantages of using an end-to-end framework like Open MLOps
Every step above could be done manually, but having the pre-built components in place lets us stick closely to MLOps principles. Using a framework assures us that our solution is:
- Easy to collaborate on: Open MLOps creates a shared understanding for our team. Because they’ve used the same platform for other projects, it’s easy for a new team member to jump in and improve something; for example, the deployment configuration (in YAML), or optimizing a specific component in Python, as a Prefect task.
- Reproducible: We save and track every training run and model we use. This means we can always figure out how we got a specific prediction or result.
- Continuous and automated: When we make changes and improvements, we don’t have to worry about human error during deployment. Our changes are automatically tested and pushed live.
- Monitored: It’s easy to check our models for decay. We’ll know exactly where to find an error if something goes wrong, and we can easily check the health of our infrastructure.
For engineers used to doing things more manually (e.g., writing Python code to wrap the model with FastAPI to create the REST API), writing all the YAML to configure Seldon can be a steep learning curve, but overall configuration is simpler, less error-prone and ensures consistency between different deployments.
The challenges we still needed to solve
Of course, a framework is not a panacea that makes building a solution as easy as snapping your fingers. We’ve still needed to adapt it for some specific needs:
- We added Redis to efficiently cache the daily JSON blob, chunk it, and convert it into a tabular format.
- We added authentication and access rules. By default, Open MLOps assumes the REST API will be used internally. We still needed to manually configure this to allow external users to sign up and access the API, using an API key.
- We allow for constantly increasing data size. The GNPS dataset is interesting because it’s constantly growing. We plan to run this solution indefinitely, so our solution needs to scale along with the input data, which gets bigger every day.
None of these adaptations are part of the current default Open MLOps configuration. But because they’re all fairly common challenges in machine learning solutions, we’ll probably add options to Open MLOps to make solving similar challenges easier.
Try Open MLOps
If you want to build and deploy your own machine learning solution, consider trying out Open MLOps. We are actively working on it, so if you run into any problems just open a GitHub issue and we’ll be there to help.