

Introduction
There are lots of articles about training and evaluating recommenders, but few explain how to overcame the challenges involved in setting up a full-scale system.
Most libraries don’t support scalable production systems out of the box. The challenges are usually:
- Predicting dynamically – When you have a very large user/items dimensionality, it can be very inefficient – or impossible – to precompute all the recommendations.
- Optimising response times – When you create predictions dynamically, the time you need to retrieve them is very important.
- Frequently updating models – When the system needs to incorporate new data as it becomes available, it’s crucial to frequently update the models.
- Predicting based on unseen data – This means dealing with unseen users or items and continously changing features.
This post will tell you how you can modify a model to extend its functionality for a full-scale production environment.
Hybrid Recommender Models Deal with Real-World Challenges Better
We use a LightFM model, a very popular python recommendation library that implements a hybrid model. It’s best suited for small- to middle-sized recommender projects – where you don’t need distributed training.
Short Recap of Different Recommender Approaches
There are two basic approaches to recommendation:
Collaborative models use only collaborative information – implicit or explicit interactions of users with items (like movies watched, rated, or liked). They don’t use any information on the actual items (like movie category, genre, etc.).
Collaborative models can achieve high precision with little data, but they can’t handle unknown users or items (the cold start problem).
Content-based models work purely on the available data about items or users – entirely ignoring interactions between users and items. - So they approach recommendations very differently than collaborative models.
Content-based models usually:
- Require much more training data (you need to have user/item examples available for almost every single user/item combination), and
- Are much harder to tune than collaborative models.
But they can make predictions for unseen items and usually have better coverage compared to collaborative models.
Hybrid Recommenders – like LightFM – combine both approaches and overcome a lot of the challenges of each individual approach.
They can deal with new items or new users:
When you deploy a collaborative model to production, you’ll often run into the problem that you need to predict for unseen users or items – like when a new user registers or visits your website, or your content team publishes a new article.
Usually you have to wait at least until the next training cycle, or until the user interacts with some item, to be able to make recommendations for these users.
But the hybrid model can make predictions even in this case: It will simply use the partially available features to compute the recommendations.
Hybrid models can also deal with missing features:
Sometimes features are missing for some users and items (simply because you haven’t been able to collect them yet), which is a problem if you’re relying on a content-based model.
Hybrid recommenders perform for returning users (those who are known from training) as well as new users/items, as long as you have features about them. This is especially useful for items, but also for new users (you can ask users what they’re interested in when they visit your site for the first time).
System Components
This system assumes that there are far fewer items than users, since it always retrieves predictions for all items. But it can serve as the basis for more complex recommenders.

The core of the system is a flask app that receives a user ID and returns the relevant items for that user. It will (re)load the LightFM model and query a redis instance for item and/or user features.
We’ll assume that user and item features are stored and serialised in a redis database and can be retrieved by the flask app at any time.
All applications will be deployed as microservices via docker containers.
How LightFM Makes Predictions

But how does it work?
The LightFM paper is very informative for an academic reader, but maybe a little brief for someone who isn’t very familiar with the domain. I’ll outline the LightFM model predicition process more simply below.
Explanation of the formulas:
- Lowercase letters refer to vectors, and uppercase letters refer to matrices.
- The subscript u refers to a single user, and U refers to the complete set of all users. Items are referred to in the same way.
Most of the naming here is consistent with the LightFM paper.
Model Components
So LightFM combines to best of the collaborative and the content-based approaches. You might say it models one component for each of the two approaches. Both are necessary to give us the properties we want from the recommender.
Collaborative component
The collaborative component allows you to fall back on a collaborative filtering algorithm in case you don’t have any features – or the features aren’t informative.
State-of-the-art collaborative filtering algorithms are implemented with a matrix factorisation. They estimate two latent (unobserved) matrix representations, which, when multiplied by each other, will reproduce the matrix of interactions for each item and user the model saw during training. Of course, there’s an error term to allow for noise and avoid overfitting.
A simple analogy: Try to factorise 12. We can do this with 2 and 6, 3 and 4, 1 and 12, etc. It’s similar for matrices.
We’ll call those matrices latent represenations, since they’re a compressed form of our interaction data.
Content-based components
The content-based component allows you to get predictions even if you have no interaction data.
LightFM incorporates user and item features by associating the features with the latent representations. The assumption is that features and latent representation are linearly related. So in vector form:
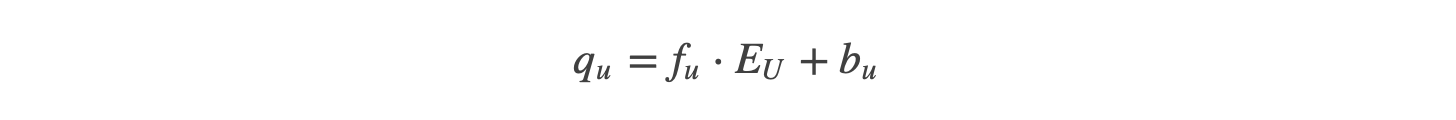
qu is the latent user representation, fu is a single user’s features row vector, Eu are the estimated item embeddings, and bu are the biases for the user emeddings. (For simplicity, we’ll leave them out from now on.)
Looks similar to linear regression, right? Except EU is a matrix, as opposed to ß, which is usually a vector. In fact, this actually performs multiple regressions: one for each model component. Again, it’s analogous for items.
During training, both the user embeddings and the item embeddings are estimated with the help of gradient descent algorithms. The embedding matrix will have a row for each feature. The columns of the embedding matrix are called components. The number of components is set as a model hyperparameter, which we’ll refer to from now as d.

The above image recaps this process for all users and all items. So in Step I, we have a matrix multiplication of the user feature matrix of shape Nusers×Nuserfeatures with the embedding matrix of shape Nuserfeatures×d. The same applies for the second multiplications of the item features by the item embeddings, respectively. The result from Step I is two matrices of shape Nusers×d and Nitems×d, respectively. So each user/item is represented as a latent vector of size d.
In the final step, these two matrices are mutliplied, resulting in the final score for each user and item of shape Nusers×Nitems.
Now you can easily get all the representations for a single user with the following term:

qu is a row vector of the user’s latent representations, and QI is a matrix of the latent representations of all items.
Enable Fallback to Collaborative Mode with Indicator Matrices
LightFM can only generate models with collaborative information.
It uses a very effective trick: If no user or item features are used at all, the model will accept an identity matrix of the size respective to Nusers or Nitems. This is very effective, since it then learns d components – one for each user. This way, the model can always fall back on the best pure collaborative method. You can think of these components as the model’s memory of the users and items it has already seen during training.
You can also force the model to fall back to collaborative mode – even when you do have features: You can modify the feature matrix by appending an identity matrix to it. Sometimes you’ll need this to get your model to converge. However, this usually means your features are too noisy or don’t carry enough information for the model to converge to a minimum by itself.
Finally, using this trick increases the effort needed to take the model to production: During training, the user’s index is used to retrieve the correct row of the corresponding feature/identity matrix – and this information might no longer be available in a production environment; plus the LightFM model hands this responsibility off to the user.
Interesting fact
The latent representations of similar items/users (in terms of collaborative information) you can obtain by using only indicator features will be close in Euclidean space. This model estimates them based on collaborative information. So you can use those to find similarities between your items or users.
Recreating Indicators and Features on the Fly

Now let’s implement a model that can fall back on collaborative mode, keeps track of IDs, and is thus able to reconstruct the correct features and indicators.
We’ll focus on implementing a complete approach. This is quite complex, because at the same time, it should be able to give predictions in most situations. We’ll subclass the LightFM class and add a special predict_online method, which is intended to be used during production.
This way, we can still use LightFM’s cythonised predictions functions and avoid handling user and item ID mappings separately.
It should satisfy these requirements:
- Reconstruct the indicator feature if the user/item was seen during training;
- Make online predictions no matter what data is available on a certain user;
- Make those predictions as quickly as possible.
ID Mappings
To achieve the first requirement, you’ll have to use the same class during training as well. You also need to adjust your subclass so it only accepts sparsity SparseFrame objects during training, and therefore creates and saves ID mappings.
Reconstructing Features
In order to achieve the second requirement, you need to check the available data every time a request comes in. There are 16 cases you’ll have to handle:

In cases IV, VIII, and XII, we simply return our baseline predictions. For cases XIII through XVI, we can’t give any predictions, because we don’t know enough about the items.
To summarise: We basically want to create a row vector which contains the user features, if they’re available. Otherwise it’s all zeros at the respective indices. It will also contain the user indicator feature set at the correct index, if the user was seen during training.
The item features are analogous to the user features, except we expect them to fit into memory easily to allow for a cache. You might consider using a different caching strategy (like TTLCache) based on your usecase, or not caching at all.
We also want to support not adding indicators, or only adding them to user or item features, which might make the implementation a little more complex. Still, we’ve tried to keep it as simple as possible.
Below you’ll find a sample implementation of the approach described above. This implementation should handle all cases up to VIII correctly. But it’s possible that not all item cases are implemented, since our application didn’t require it. So predicting known items without item features isn’t possible, but it should be very easy to add.
Part II of this post uses this class, connects it to a redis database, and serves its prediction dynamically with flask. We’ll also show you how to update the model without downtime with a background thread that starts from within in the flask application.
Implementation
<p> CODE: https://gist.github.com/Haikane/a630915f267f68b7e79526ebdcfc53d0.js</p>